Project Overview
This project develops a robust and privacy-preserving Human Activity Recognition (HAR) system using multi-band Channel State Information (CSI) from the FR3 spectrum (7–24 GHz). Whereas existing sensing systems rely on a single frequency band and exhibit strong susceptibility to environmental variation, this work exploits the complementary propagation characteristics of the bands between 7 GHz and 24 GHz to improve robustness and accuracy.
The system is built on an Integrated Sensing and Communication (ISAC) paradigm, where wireless signals are simultaneously used for data transmission and environmental sensing. A Software-Defined Radio (SDR) platform based on USRP X310 units collects synchronized CSI streams through time-division multiplexing, enabling dual-band fusion (10 GHz and 15 GHz) without hardware duplication. The system integrates a complete data collection pipeline, machine learning models for activity classification, and systematic evaluation across four progressively larger datasets.
Datasets
We collected four datasets totaling over 80,000 labeled CSI samples. Each sample consists of complex-valued channel measurements across 250 subcarriers, 4 spatial streams, and 2 frequency bands.
| Dataset | Users | Activities | Samples | Sessions | Description |
|---|---|---|---|---|---|
| Chair | – | 2 | ~1.1K | 2 | Binary chair detection (vacant / occupied) |
| JTerm | 1 | 10 | ~33K | 100 | Single-user, 10 activities, T=32 time frames |
| Sunday | 3 | 9 | ~9.2K | 28 | Multi-user, 9 activities, sequential captures |
| Saturday | 7 | 17 | ~39K | 56 | Multi-user, 17 activities, 2 furniture orientations |
All datasets were collected in the NYU Abu Dhabi Wireless Research Lab using a pair of USRP X310 SDRs. The Sunday and Saturday datasets are particularly significant because their samples were collected with sufficient temporal separation to avoid the intra-capture correlation that plagues high-frequency CSI recordings.
We train lightweight CNN classifiers (594 to 1.2M parameters) as well as logistic regression baselines, evaluating across tasks including HAR, User Detection (UD), and joint User+Activity classification (UDHAR).
Key Findings
Our central finding is that standard random train/test splits produce artificially inflated accuracy (~100%) because temporally adjacent samples from the same recording session leak across the split. We demonstrate this through five capture-aware evaluation strategies:
- LOCO (Leave-One-Capture-Out): Accuracy drops to ~57% when no recording session appears in both train and test sets.
- Controlled Leakage (Leak-1): Adding just 1 sample per held-out capture recovers 94.3% – the smoking gun proving models memorize per-capture CSI fingerprints, not activity patterns.
- Temporal Splits: Training on earlier recordings and testing on later ones achieves 73–88%, confirming that temporal proximity drives the inflated scores.
- LOUO (Leave-One-User-Out): Accuracy drops to 13–18% (9-class HAR), revealing that models memorize user-specific RF signatures rather than learning generalizable activity features. Even collapsing to 3 broad activities (sit/stand/walk) only reaches 36%.
- Furniture orientation shift: Training on one room layout and testing on another drops accuracy to 14.6% (near chance at 1/17). However, this gap is extremely data-efficient to bridge: mixing just 5% of target-orientation data recovers 78%, and 10% reaches 97%.
Results
In-Distribution Performance
When trained and tested on random splits of the same dataset, all models achieve near-perfect accuracy – but this is misleading due to temporal leakage.
| Dataset | Task | Model | Random-Split Accuracy |
|---|---|---|---|
| Chair | HAR | femto_cnn (594 params) | 100.0% |
| Chair | HAR | kilo_cnn (1.2M params) | 100.0% |
| JTerm | HAR | milli_cnn (74K params) | 99.1% |
| JTerm | UD | logreg | 99.6% |
| Sunday | HAR | kilo_cnn | 94.0% |
| Sunday | UD | kilo_cnn | 98.0% |
| Sunday | UDHAR | kilo_cnn | 92.9% |
These numbers are the benchmark – but they reflect dataset-specific memorization rather than true generalization, as the following evaluations demonstrate.
Architecture × Task × Frequency
A key design question is whether dual-band fusion (10 + 15 GHz) outperforms single-band operation. We compared five architectures across three tasks (HAR, UD, UDHAR) with three frequency configurations across the Sunday dataset:
- Both bands consistently matches or outperforms the best single band in every task and architecture.
- Larger models help for in-distribution performance: kilo_cnn (1.2M) achieves 94.0% vs nano_cnn (7K) at 69.5% for HAR. However, this advantage disappears under domain shift.
- UD is the easiest task – even nano_cnn reaches 89.6% with both bands.
- 15 GHz alone (f2) consistently underperforms 10 GHz (f1) and the dual-band combination, which is expected given 15 GHz’s higher path loss and reduced diffraction around the body.

In-Distribution Confusion Matrices
The confusion matrices for the Sunday dataset under random-split evaluation show strong diagonal dominance. For HAR (10 classes including “baseline” with no user present), kilo_cnn achieves 94.0%. For UD (4 classes: 3 users + nouser), accuracy reaches 98.0%.


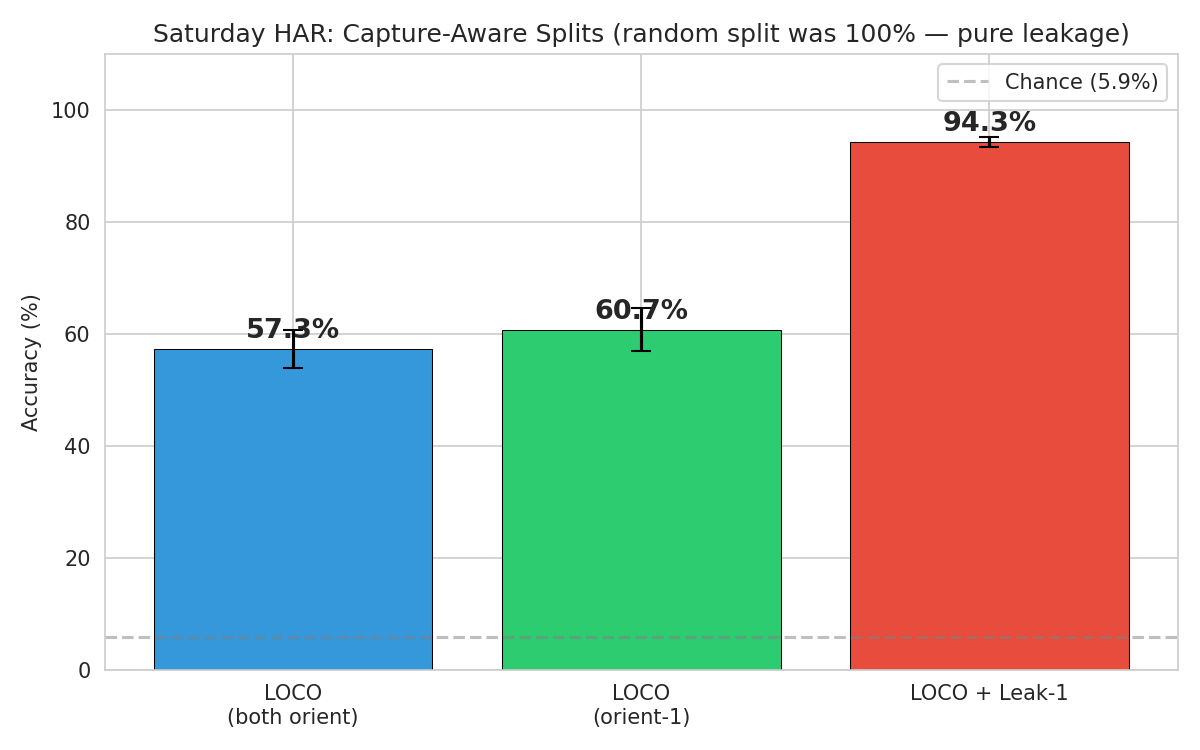
Capture-Aware Splits
The Saturday dataset has 4 independent capture sessions per furniture orientation. However, each capture produces 32 consecutive CSI windows separated only by milliseconds – these are not truly independent samples but near-identical snapshots of the same instant. A random split will place some of these windows in training and the rest in testing, allowing the model to memorize per-capture fingerprints.
LOCO isolates one capture session at a time for testing, ensuring no temporal leakage. Leak-1 adds just a single sample from the held-out capture back into training.
| Variant | Mean Accuracy |
|---|---|
| LOCO (both orientations) | 57.3% |
| LOCO (orient-1 only) | 60.7% |
| LOCO + Leak-1 | 94.3% |
LOCO achieves ~57% on average. Adding just one sample per capture (Leak-1) recovers 94.3%. This conclusively demonstrates that the inflated random-split accuracy is driven by per-capture CSI fingerprints and not activity-relevant features.
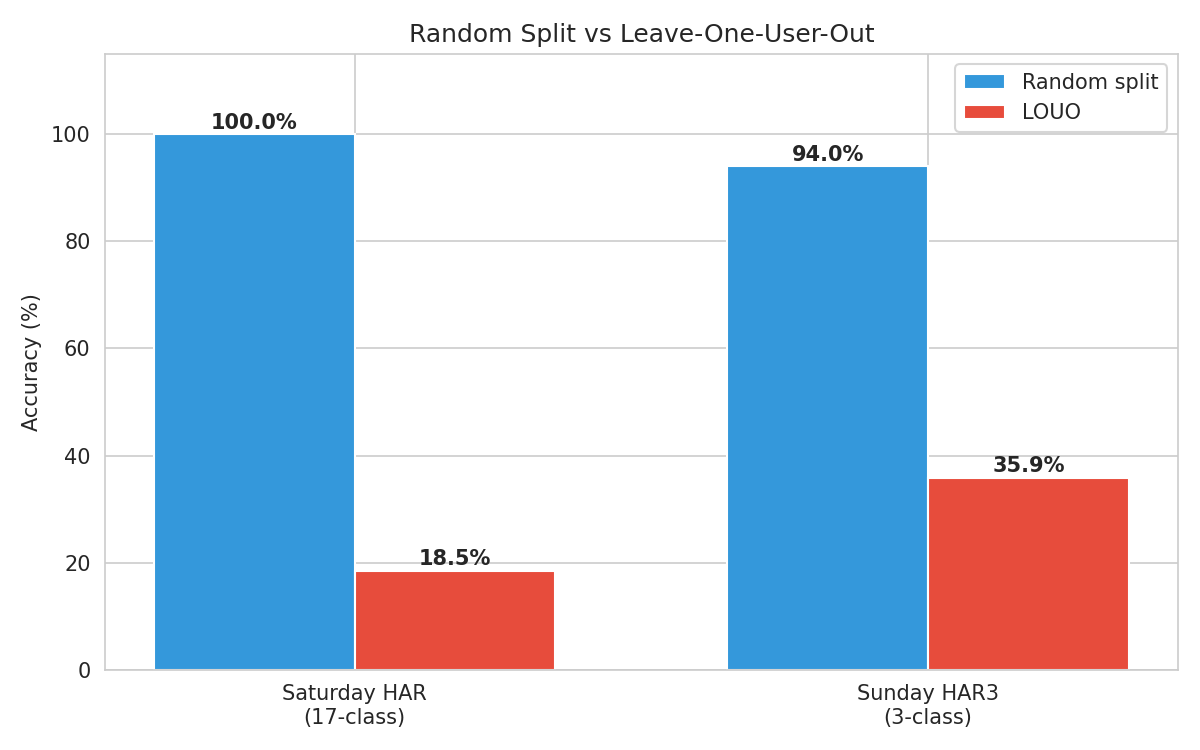
Random Split vs. Leave-One-User-Out
LOUO holds out one user entirely and trains on the remaining users. This tests whether the model learns generalizable activity patterns or simply memorizes user-specific RF signatures.
| Dataset | Task | Random Split | LOUO |
|---|---|---|---|
| Saturday | HAR (17-class) | 100.0% | 18.5% |
| Sunday | HAR (9-class) | 94.0% | 13.5% |
| Sunday | HAR3 (3-class) | ~96% | 35.9% |
Even collapsing to just 3 broad activity categories (sit, stand, walk), cross-user accuracy only reaches 36%, suggesting that user-specific body dynamics and CSI signatures dominate what the model learns. Including a “nouser” baseline capture in the training set provides marginal improvement (17.2% vs 13.5% for 9-class HAR).
Domain Adaptation for User Invariance: CSI Transforms and DANN
We explored two strategies to make the model invariant to user identity:
Physics-motivated CSI transforms aim to strip user-specific components while preserving activity-relevant structure. We tested 9 transforms including temporal differencing, Doppler, amplitude ratio, and temporal statistics:
| Transform | LOUO Accuracy (HAR3) |
|---|---|
| None (baseline) | 35.9% |
| Amplitude ratio | 35.5% |
| Doppler | 34.8% |
| Temporal stats | 33.9% |
| Temporal diff | 33.8% |
| Doppler (double) | 33.6% |
| Temporal variance | 33.1% |
| Mean-subtract diff | 31.6% |
| Temporal mean sub | 31.0% |
None of the transforms significantly outperformed the baseline, indicating that user-specific information is deeply embedded in the CSI structure and cannot be removed by simple deterministic operations.
Domain-Adversarial Neural Networks (DANN) add a gradient reversal layer that forces the encoder to produce features that cannot predict user identity. On 3-class HAR:
| Method | LOUO Accuracy (HAR3) |
|---|---|
| Baseline | 35.9% |
| DANN (adv_weight=1.0) | 34.3% |
| DANN (adv_weight=0.3) | 34.3% |
DANN provided no improvement over the baseline for 3-class HAR, and similarly marginal results for 9-class HAR (18.3% vs 13.5% baseline) and Doppler input (13.7%). The gradient reversal signal is apparently too weak to overcome the strong user-specific signature present in the raw CSI.
Few-Shot User Calibration
Since full user invariance proved challenging, we evaluated a practical alternative: few-shot calibration using K labeled samples per class from the held-out user. This simulates a realistic deployment scenario where a new user provides a brief calibration routine.
| K (samples/class) | LOUO After Calibration | Frozen Backbone |
|---|---|---|
| 1 | 25.3% | – |
| 5 | 48.8% | 55.3% |
| 10 | 55.4% | 58.0% |
| 20 | 66.3% | 65.6% |
| 30 | 73.6% | 65.6% |
| 50 | 81.4% | 67.6% |
| 80 | 86.2% | 69.6% |
| 128 | 91.0% | 71.1% |
Key insights:
- With just 5 samples per class (~40 seconds of data), accuracy jumps from 13.5% to 48.8%.
- 128 samples per class (~16 seconds per activity) reaches 91.0% – nearly matching in-distribution performance.
- Frozen backbone (tuning only the classifier head) works well at low K but plateaus earlier, suggesting fine-tuning the full network is beneficial with sufficient calibration data.
- Combining DANN pre-training with few-shot calibration does not outperform fine-tuning from scratch (DANN+fs50 = 80.3% vs plain fs50 = 81.4%).
UDHAR with Evaluation Collapse
Joint user+activity training (UDHAR) with evaluation collapse to HAR tests whether compound labels help disentangle user and activity factors. The compound-to-HAR collapsed accuracy is 17.3% for kilo_cnn – similar to direct HAR LOUO (13.5%). This suggests that the multi-task formulation does not inherently separate user and activity factors.
Pairwise Class Separability
We used binary logistic regression to measure separability between every pair of 9 activities and between every pair of 27 user+activity classes.
Activity pairs (HAR): Most activity pairs are highly separable (90–98%) within the same user/session, but confusing pairs reveal genuinely similar physical motions:
stand_rightvswalk_left: 56.4% (worst pair – transitioning between these involves similar postures)walk_leftvswalk_right: 65.9% (direction of walking is hard to distinguish)sit_rightvswalk_right: 60.1%sit_rightvswalk_left: 63.4%
Cross-user pairs (UDHAR): The same activity across different users is often highly separable (70–90%), confirming that user identity strongly shapes the CSI signature. For example, abdullah_walk_middle vs aleks_walk_middle is 59.0% separable despite being the same activity, while abdullah_walk_right vs aleks_sit_left is 89.6% separable despite being different activities. This explains why LOUO generalization is so poor: the inter-user variation for the same activity can exceed the intra-user variation across different activities.
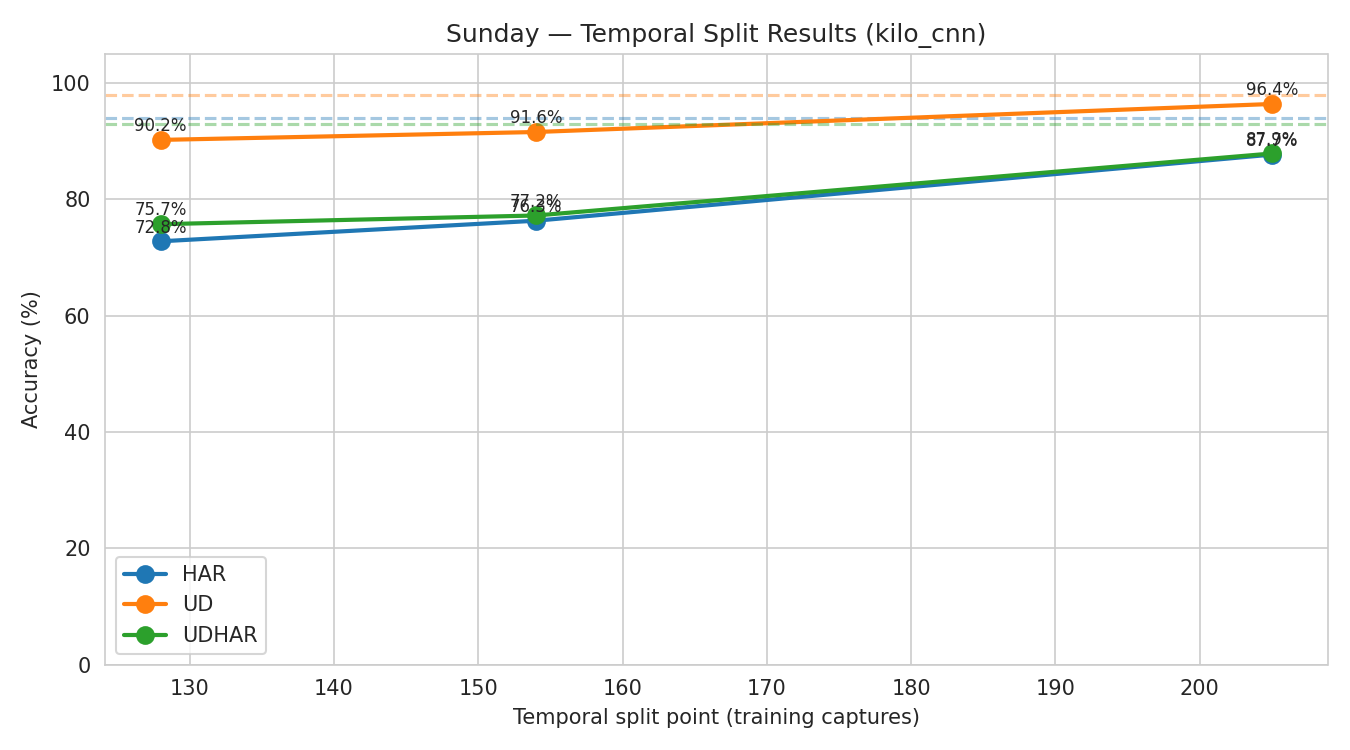
Temporal Splits
Temporal splits order all captures by recording time and train on early captures, test on later ones. This evaluates whether models generalize across time.
| Split Point | HAR | UD | UDHAR |
|---|---|---|---|
| 128 captures (early) | 72.8% | 90.2% | 75.7% |
| 154 captures | 76.3% | 91.6% | 77.2% |
| 205 captures (late) | 87.7% | 96.4% | 87.9% |
The dashed lines show the (leaky) random-split baseline for each task. Temporal accuracy is well below random-split performance but higher than LOUO, indicating that time-varying environmental factors matter less than user identity.
Cross-Session Generalization (Ctrl experiments)
We systematically measured how much same-environment data is needed to generalize to a held-out capture session:
- Ctrl_same (some labeled data from target): accuracy climbs from 17.9% (1% of target) to 90.9% (100% of target).
- Ctrl_cross (no target data): at best reaches 15.9% with 10% of another session’s data.
This mirrors the LOCO finding: without data from the target capture, the model cannot generalize. With even a small fraction of target data, accuracy recovers rapidly.
Furniture Orientation Gap
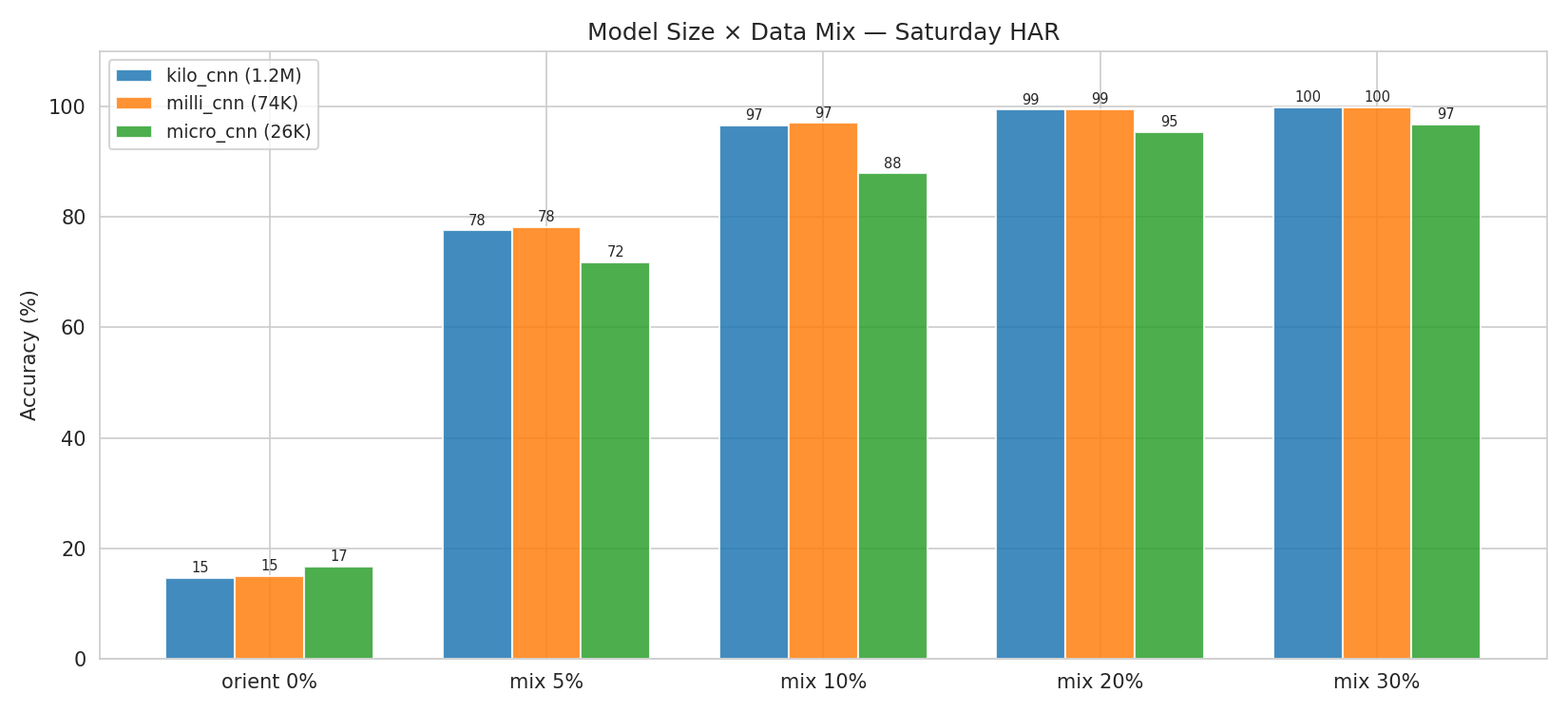
The Saturday dataset was collected in two distinct furniture layouts with 7 users performing 17 activities in each layout. Training on orientation 1 and testing on orientation 2 drops accuracy to 14.6% (near chance at 1/17).
However, this domain gap is remarkably cheap to bridge. Adding just a small fraction of labeled orientation-2 data produces an S-curve of recovery:
| Mix Ratio | kilo_cnn | milli_cnn | micro_cnn |
|---|---|---|---|
| 0% (pure orient-1) | 14.6% | 15.0% | 16.8% |
| 1% | 42.7% | 24.0% | 20.4% |
| 2% | 60.0% | 50.0% | 52.2% |
| 3% | 69.9% | 74.5% | 63.2% |
| 4% | 81.4% | 72.6% | 68.6% |
| 5% | 77.6% | 78.2% | 71.8% |
| 7% | 92.1% | 91.8% | 79.9% |
| 8% | 95.2% | 93.8% | 83.0% |
| 10% | 96.6% | 97.0% | 87.9% |
| 20% | 99.4% | 99.5% | 95.4% |
| 30% | 99.8% | 99.8% | 96.8% |
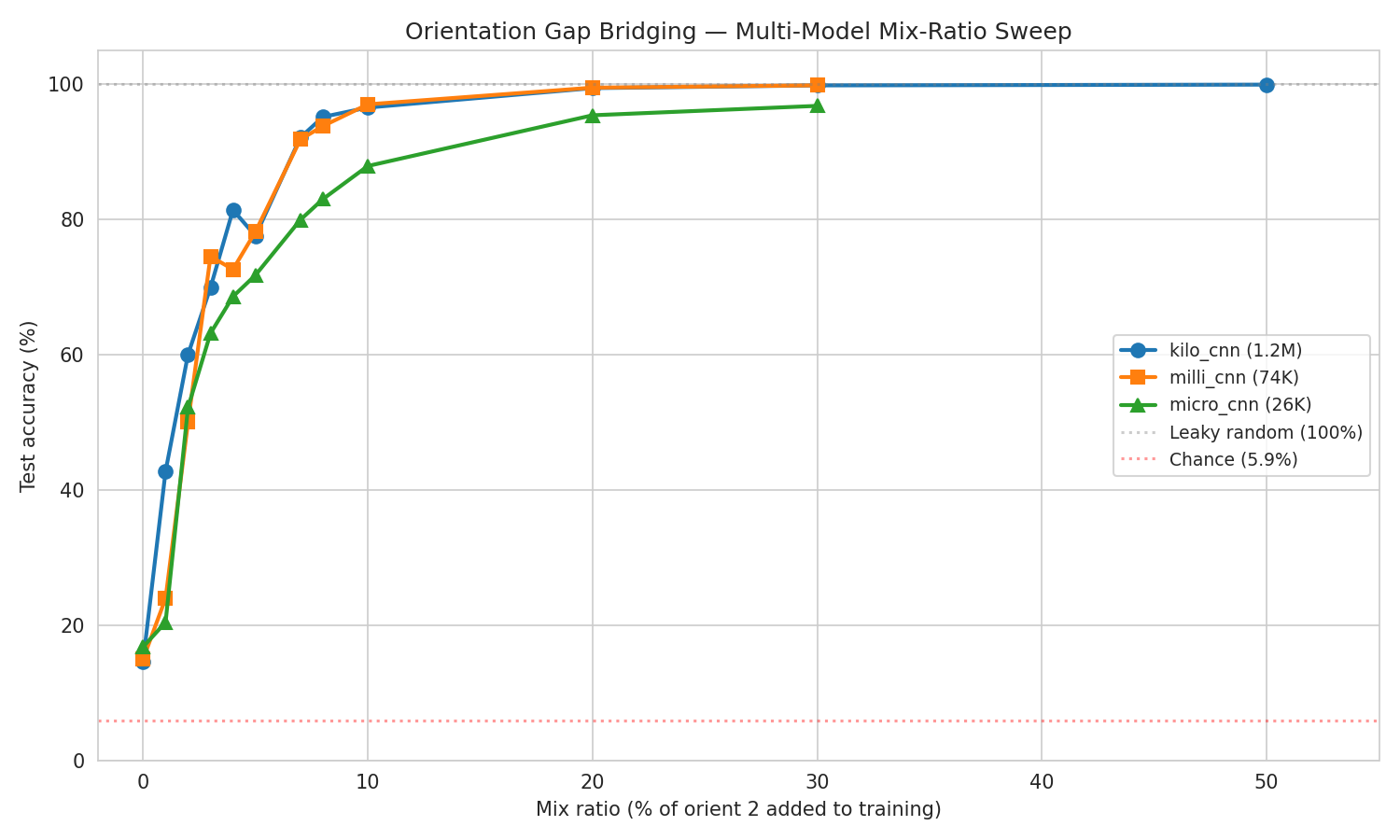
Key insights:
- The S-curve is steepest between 2–8% labeled data, where accuracy jumps from ~50% to ~95%.
- Model size barely matters: milli_cnn (74K params) matches kilo_cnn (1.2M) at every mix ratio.
- Few-shot fine-tuning on top of the orientation-split baseline is completely ineffective (14.6–14.7% regardless of K), because the baseline model has learned nothing about the target domain.
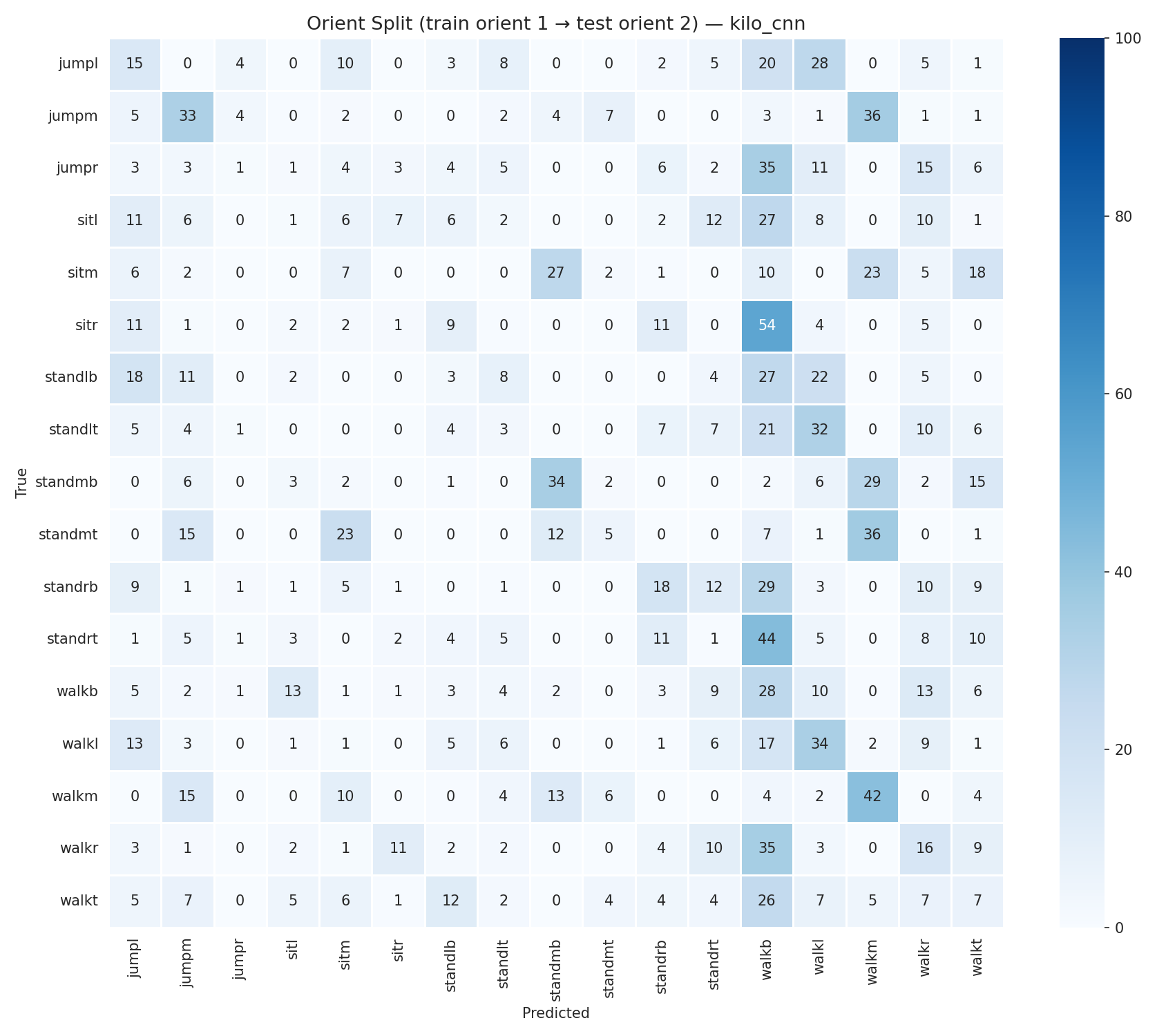
The confusion matrix at 0% mixing (pure orient-1 training, orient-2 test) reveals near-uniform predictions, confirming the model is essentially guessing:
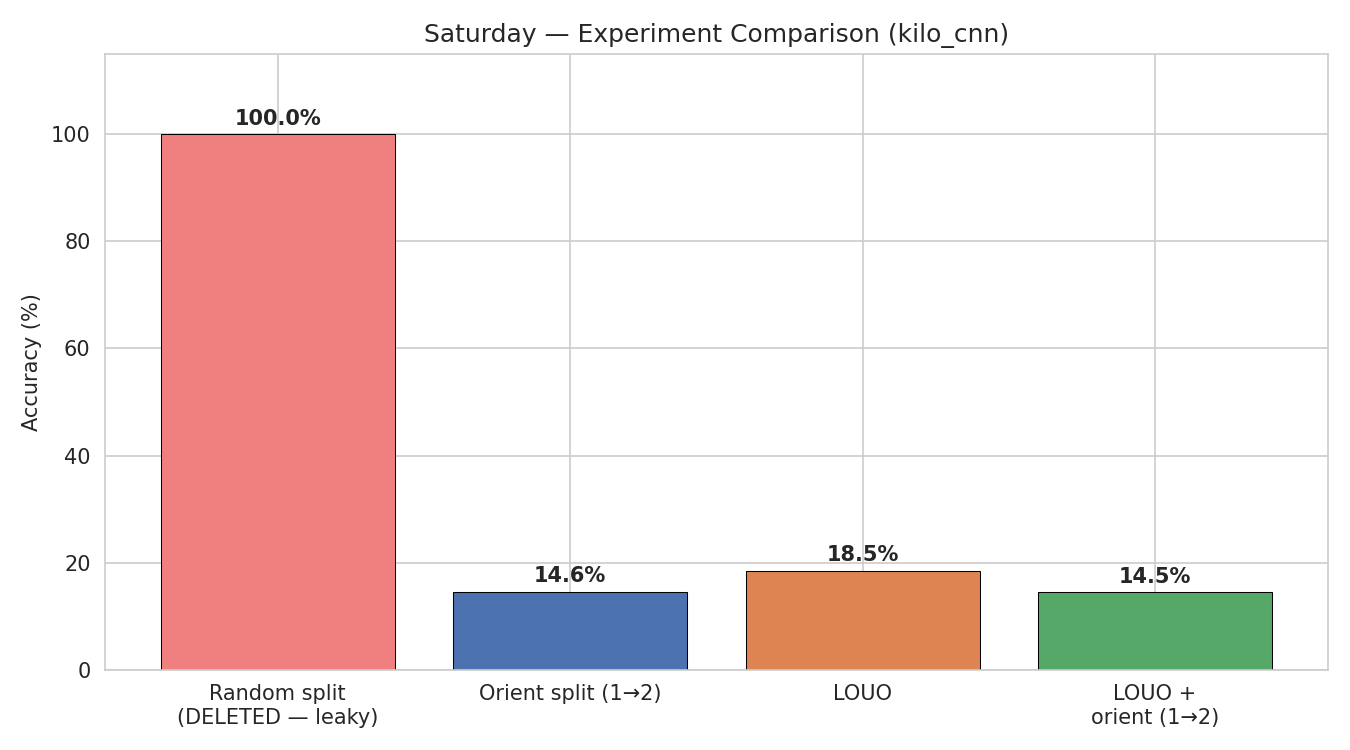
Saturday Evaluation Strategies
All Saturday evaluation strategies compared side by side reveals a clear hierarchy of generalization difficulty:
| Strategy | Accuracy | What It Measures |
|---|---|---|
| Random split | ~100% | Temporal leakage (inflated) |
| LOCO + Leak-1 | 94.3% | Session-specific fingerprints |
| LOCO (orient-1) | 60.7% | Cross-session + cross-user |
| LOCO (both) | 57.3% | Cross-session generalization |
| LOUO | 18.5% | Cross-user generalization |
| LOUO + orient split | 14.5% | Cross-user + cross-layout |
| Orient split (1→2) | 14.6% | Cross-layout generalization |
Model Zoo
We implemented 9 CNN architectures spanning five orders of magnitude in parameter count, all designed for the unique (C, T, S) input structure:
| Model | Parameters | Description |
|---|---|---|
| logreg | ~3.5K | Logistic regression (linear classifier) |
| femto_cnn | 594 | Minimal 2-conv CNN, lower-bound probe |
| pico_cnn | ~1.2K | Slightly wider femto for edge deployment |
| nano_cnn | ~7K | 3-conv with pooling, resists noise overfit |
| micro_cnn | ~26K | 4-conv, moderate width |
| milli_cnn | ~74K | 4-conv, wider channels |
| kilo_cnn | ~1.2M | 5-conv with residual connections |
| resnet18 | ~11M | Full ResNet18 adapted for CSI, adaptive pooling |
| resnet34 | ~21M | Deeper ResNet34 |
Despite the wide range, model size barely matters for generalization: milli_cnn (74K) matches kilo_cnn (1.2M) on the orientation mix-ratio sweep, and even femto_cnn (594 params) achieves perfect accuracy on the chair detection baseline. The bottleneck is not model capacity but the fundamental domain shift across captures, users, and environments.
Discussion
The Leakage Problem
The single most important finding of this project is that random splits are meaningless for CSI-based activity recognition when recordings contain high-frequency contiguous frames. Temporally adjacent samples share the same underlying channel conditions, user position, and environmental state, so the model simply memorizes per-capture fingerprints. This is conclusively demonstrated by the Leak-1 experiment: adding one sample per held-out capture recovers 94.3% from 57.3%.
This has implications for the broader wireless sensing community: any published result using random splits without capture-aware evaluation should be treated with skepticism. We recommend that future work always evaluate with LOCO or LOUO protocols.
Generalization Is Hard
Cross-user generalization remains the hardest challenge. Even with 3 broad activity classes (sit, stand, walk), LOUO accuracy only reaches 36%, and none of our domain adaptation strategies (CSI transforms, DANN, UDHAR multi-task learning) improved this meaningfully. User-specific body geometry, tissue composition, and movement dynamics create distinct CSI signatures that dominate over the common activity patterns. The pairwise separability analysis confirms this: cross-user same-activity pairs are as separable as different-activity pairs.
Practical Path: Few-Shot Calibration
The most practical path to deployment is few-shot calibration: collecting a small amount of labeled data from each new user. With just 5 samples per class (~40 seconds), accuracy jumps from 13.5% to 48.8%, and 128 samples per class (16 seconds per activity) reaches 91.0%. This is feasible in real-world deployments where a user briefly performs each activity during initial setup.
Orientation Robustness Is Data-Efficient
The furniture orientation domain gap is severe (14.6%) but extremely data-efficient to bridge: 5–10% of target-layout data recovers 78–97% accuracy. This suggests that orientation shifts affect a relatively low-dimensional subspace of the CSI features, making them easy to correct with minimal additional data. Model size does not affect this – all architectures follow nearly identical recovery curves.
Model Architecture
Through the full model zoo, we found that model capacity is not the limiting factor for CSI-based activity recognition. A 594-parameter femto_cnn matches kilo_cnn (1.2M) on chair detection, and milli_cnn (74K) matches kilo_cnn on every generalization metric. This is encouraging for embedded deployment: the best strategy is a lightweight model with a practical calibration procedure, not a larger model.
Conclusion
This project systematically demonstrates that standard evaluation practices overestimate CSI-based activity recognition by a wide margin. The true generalization challenge is cross-user and cross-environment recognition, where accuracy drops from ~100% (random split) to 14–18%. Practical deployment requires either few-shot calibration (achieving 91% with 128 samples/user) or robust domain adaptation that remains an open research problem. The orientation domain gap, while severe, is remarkably data-efficient to bridge. Model size has minimal impact on generalization, suggesting that lightweight architectures with calibration-based deployment are the most promising path forward.
Supervised by: Prof. Marwa Chafii, Dr. Roberto Bomfin, and PhD Candidate Salmane Naoumi
Tech: Python (PyTorch), MATLAB, USRP X310 SDR